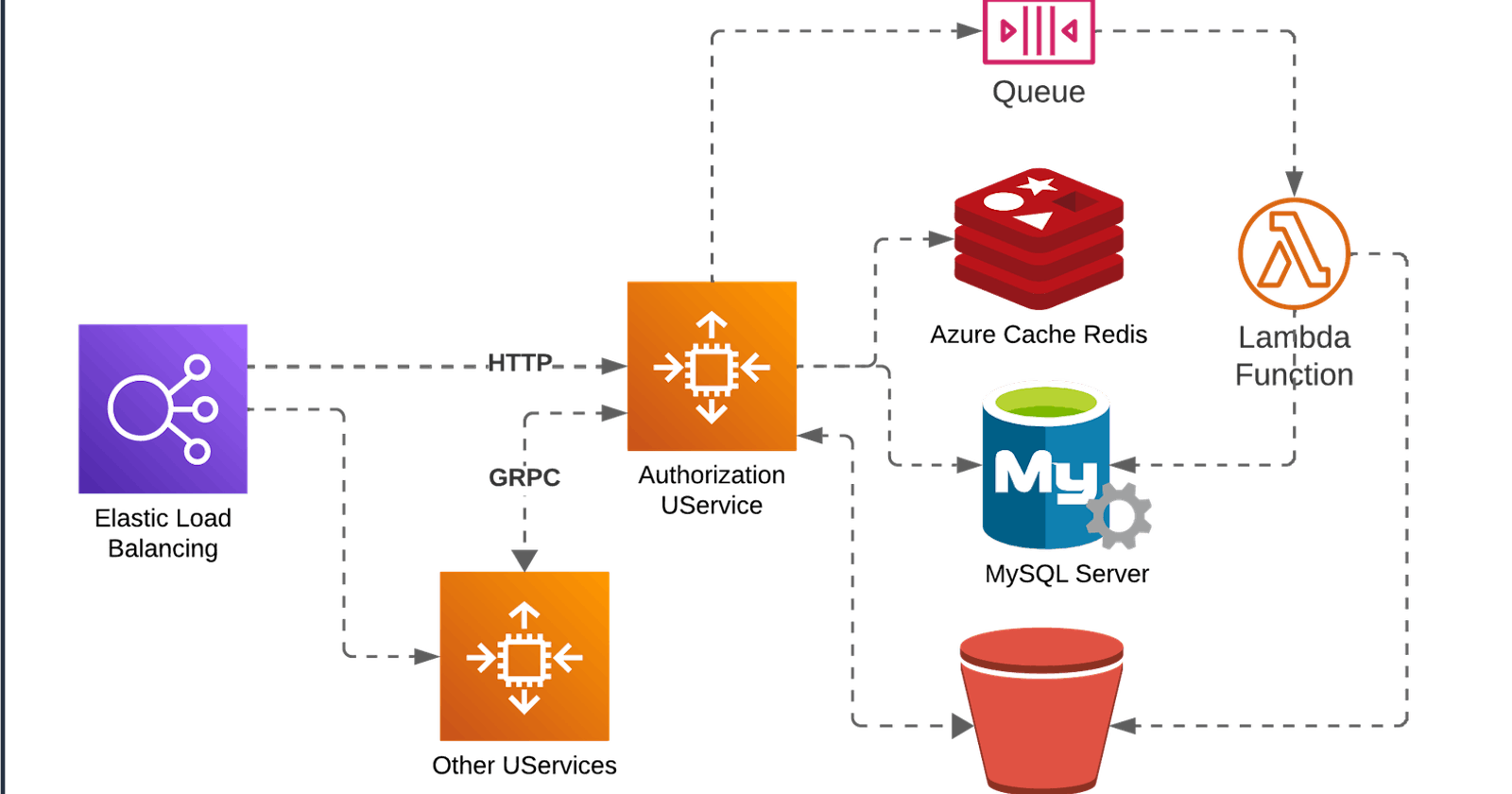


Before we dive deep into implementations, it is a great idea to sketch our system's architecture design. Again, this is not written in stone, and even the tools might change along the way. Either way, I will address my choices for architecture and technology.

Load Balancer
The Load Balancer works as the entry point for our application. It provides several critical features, such as distributing and redirecting traffic to appropriate services (reverse proxy), implementing SSL encryption, triggering scaling out of services, monitoring other services' health, and even protecting the system against DDoS attacks. The most used Load Balancer application out there is Nginx, but as I am planning to deploy this system on AWS, I will use the provider's Load Balancer. In later articles, I will explore the Load Balancer Features and configurations further.
The Authorization Service
For the authorization service, I will use NodeJS with TypeScript. Although some changes might occur during the development of this project, I would rather use strongly typed (TypeScript) code for two reasons:
Facilitate maintenance and use by other developers.
Decouple components within the application.
Some people might argue that code written in loosely typed languages can be as easy to use and maintain as strongly typed code as long as it is well documented and tested. Well, I have worked on several projects, and although the usage of code lines can help, it is another level of extra care that must be enforced.
So, if I am an enthusiast of strongly typed code, why would I choose NodeJs then? Well, I am in a hurry, and NodeJS has a huge community and a lot of packages available at NPM that can help me out. Also, I am still thinking about developing a frontend for this application, and It will be nice if they are written in the same language (JavaScript).
Note in the diagram that the Authorization Service block has two connections in its left side. The first one points to the Load Balancer. This connection exposes a REST API for users to access directly. The second points to other services using GRPC. I could have chosen to go full REST, but in this project, I wanted to learn something new, and it seemed like a good application for the GRPC framework. To create some context, GRPC is implemented over HTTP/2 and uses binary payload format instead of the heavyweight JSON. Also, the GRPC enables bidirectional communication which is super useful in a Micro Service Architecture.
Database
To store the information related to this project, I will use a relational Database. Maybe later, I will add a NoSQL database for logging and report generation, but right now, for the main functionalities, I prefer to stick with the enforced data consistency of a Relational Database. I will go with MySQL just because of familiarity.
Caching and Queueing
To increase the performance of this system, I am planning to use some in-memory cache. This will be further explored in future posts. In the first versions of the system, I might start with only a MemCache library, but later, Redis will be used not only for caching but also for queueing tasks related to report generation.
Serverless
Another component that I am adding to this project in order to practice something new is Serverless processing. This component will be used to generate reports and store them. The idea here is that reports will only be processed every once in a while. Therefore, having a dedicated server for processing such reports would be a waste. Also, imagine that a certain company is being audited, and many reports are requested on the same day. In this scenario, Serverless processing is useful since they are inherently scalable and will only charge while they are running. Another great aspect of using Serverless processing for report generation is the flexibility of developing and maintaining reports without touching the Authorization Service code base. This isolation is particularly useful when different customers have different demands for reports.
Blob Storage
Finally, our last system component is a Blob Storage. Generated reports are expected to hold extensive amounts of data, most of the time already structured data in the form of an .XML or .XLS file. These reports may be stored for long periods of time, and customers may want to download them without having to generate that data all over again. To store such files, we will use a Blob Storage, which in the AWS environment is an S3 bucket. In later articles, we might discuss different tiers of Blob Storage and how to avoid extra costs with cloud providers.
This article presented a brief overview of this project's system design. I hope you enjoyed it.